Your Database isn't Anonymous
At first glance, it seems that the simplest approach to providing privacy for databases is just to make those databases anonymous. The database holder could simply remove or obscure any identifying features like name, zipcode and age before releasing it.
As attractive as this idea might be, in the early days of data privacy it led to an unfortunate pattern that repeated itself again and again. The pattern began with a database being anonymized and released using the latest and greatest anonymity guarantee. Then, almost inevitably, someone would show that they could identify individuals from the supposedly anonymous database.

This led to a progression of definitions of anonymity, all of which ultimately fell short in some crucial way. These shortcomings were usually attributed to one of two main underlying issues:
- Other databases may exist that contain overlapping information or individuals. It is usually extremely hard to find out about all existing (and future) databases of this form.
- Data is often sparse and high-dimensional.
In this post, we are going to discuss some of these definitions alongside some famous cases of broken anonymity.
- K-anonymity
- L-diversity and T-closeness
- Famous Reconstruction Attacks
- How Does Differential Privacy Help?
k-Anonymity
In 1998, Samarati and Sweeney proposed an approach to releasing data privately using their idea of k-anonymity:
A table provides k-anonymity if attempts to link explicitly identifying information to its contents ambiguously map the information to at least k entities.
This definition is based on finding:
- Identifiers: attributes that unambiguously identify an individual and should be removed.
- Quasi-identifiers: attributes that may be used to re-identify an individual and therefore need to be altered so that any combination of these is k-anonymous.
For example, identifiers could be a person’s full name and social security number, quasi-identifiers could be age and zip code. Suppose in this case, the sensitive attribute we are trying to learn about using the database is salary. K-anonymity would ensure that no specific combination of the reported age and zip code would single out fewer than k possible entries, thus obscuring the salary of any individual who contributed to the database.
This could be achieved by removing the obvious identifiers and ‘fuzzing’ the quasi-identifiers. For example, removing a person’s name and social security number, and placing their age into sufficiently large age brackets.
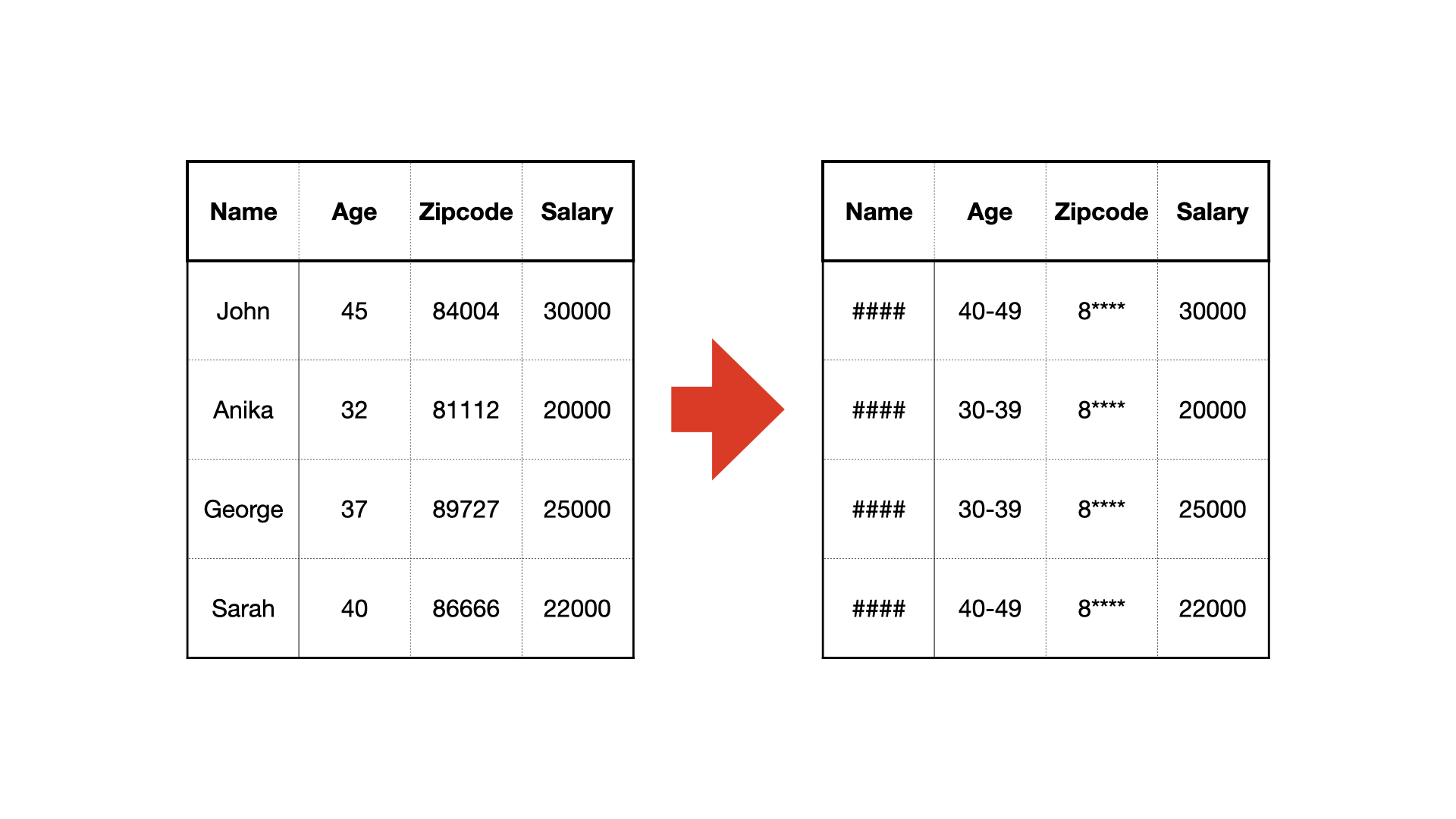
While k-anonymity was an promising step towards a definition of privacy, it was vulnerable to several varieties of attacks including those using background knowledge not identified when the anonymity was implemented and when the attributes themselves did not vary enough. For example, if the disease a person has is 4-anonymous and all four people happen to have cancer, then the sensitive attribute has not been successfully hidden.
L-diversity and T-closeness
Various extensions to k-anonymity were proposed, addressing the weaknesses identified. Machanavajjhala et al. proposed an extension of k-anonymity, l-diversity, that fixed the issue of attributes not varying enough to maintain privacy. However, l-diversity was again found be less private than expected under certain circumstances. In particular, suppose the distribution of values for a certain attribute is skewed. Only 1% of an overall population has a given disease but in a particular set of k entries, 50% have the disease. Then this group of k would satisfy 2-diversity but would also reveal more about the individuals than intended.
T-closeness was then proposed, addressing the issue of a skewed distribution of attributes by requiring that the distribution of values in any group of k-indistinguishable entries matches that of the overall database. Unfortunately, it was found to severely limit the utility of the resulting database as it effectively destroys the correlations between key attributes and the confidential attribute.
Famous Reconstruction Attacks
There have been a few blockbuster failures in the world of anonymous databases (pun intended). Famously, Netflix released a database of movie ratings associated with anonymous customer IDs. Regrettably, the database wasn’t as anonymous as they had originally thought, as records could be re-associated with individuals using information from a similar public database of IMDb ratings.
Other examples:
- Voting data was used to re-identify medical information associated with specific individuals from a Massachusetts hospital by matching the remaining exposed information [1].
- In 2006, AOL released search data with anonymous IDs to obscure the users who made each query. However, this proved unsafe as many users had previously queried their own name and so could be easily re-identified [2].
- 87% of the population could be re-identified from 1990 US Census data by simply looking at the combination of each birthday, zipcode and gender [3].
Reconstruction attacks on anonymous databases are not yet a thing of the past. Recently Zachary Schutzman, Matthew Joseph and Travis Dick showed how to break Diffix’s anonymity guarantees [4].
How Does Differential Privacy Help?
Anonymity can be a dangerously misleading guarantee, but why would Differential Privacy be any better? It turns out that Differential privacy has a few key strengths in comparison to anonymity:
- Differential privacy works regardless of the external knowledge available to the adversary. An attacker can know everything except the single row in question. They can even know all other entries in the database, and still can’t reconstruct the private row of data.
- Differential privacy requires explicit mathematical proofs of its guarantee. Difficulties in the high-dimensional or sparse case are exposed at this point.
See this blogpost for more information on Differential Privacy.